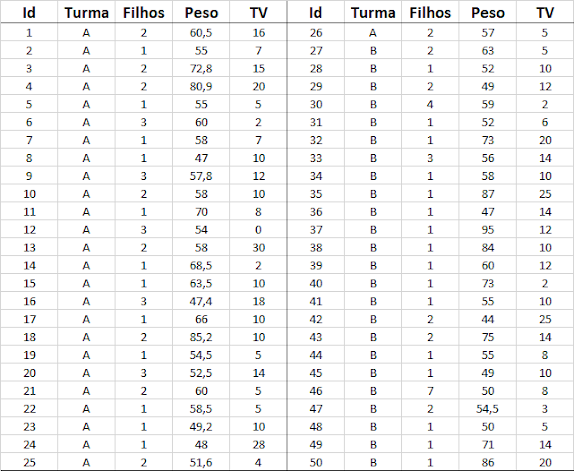
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
X, y_true = make_blobs(n_samples=300, centers=2, cluster_std=1.5, random_state=0)
kmeans = KMeans(n_clusters=2, n_init='auto')
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
centers = kmeans.cluster_centers_
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
Z = kmeans.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(figsize=(10, 6))
plt.contour(xx, yy, Z, colors='red', linewidths=2, linestyles='--')
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis', alpha=0.7, edgecolors='k')
#plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, marker='X')
#plt.xlabel('Coordenada X')
#plt.ylabel('Coordenada Y')
plt.legend()
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()
 |
| Saída gerada |